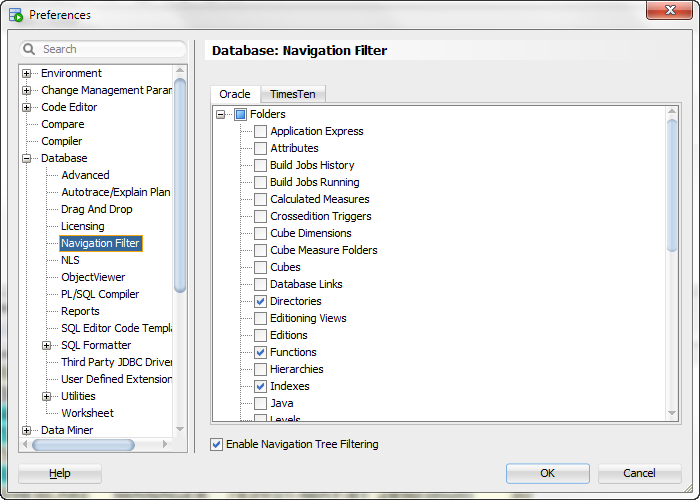
This guest post from Arun Kumar, a graduate student in the Department of Computer Sciences at the University of Wisconsin-Madison, describes work done during his internship in the Oracle Advanced Analytics group.
Oracle R Advanced Analytics For Hadoop (ORAAH), a component of Oracle’s Big Data Connectors software suite is a collection of statistical and predictive techniques implemented on Hadoop infrastructure. In this post, we introduce and explain techniques for a popular machine learning task that has diverse applications ranging from predicting ratings in recommendation systems to feature extraction in text mining namely matrix completion and factorization. Training, scoring, and prediction phases for matrix completion and factorization are available in ORAAH. The models generated can also be transparently loaded into R for ad-hoc inspection. In this blog, post we describe implementation specifics of these two techniques available in ORAAH.
Motivation
Consider an e-commerce company that displays products to potential customers on its webpage and collects data about views, purchases, ratings (e.g., 1 to 5 stars), etc. Increasingly, such online retailers are using machine learning techniques to predict in advance which products a customer is likely to rate highly and recommend such products to the customers in the hope that they might purchase them. Users build a statistical model based on the past history of ratings by all customers on all products. One popular model to generate predictions from such a hyper-sparse matrix is the latent factor model, also known as the low-rank matrix factorization model (LMF).
The setup is the following – we are given a large dataset of past ratings (potentially in the billions), say, with the schema (Customer ID, Product ID, Rating). Here, Customer ID refers to a distinct customer, Product ID refers to a distinct product, and Rating refers to a rating value, e.g., 1 to 5. Conceptually, this dataset represents a large matrix D with m rows (number of customers) and n columns (number of products), where the entries are the available ratings. Notice that this matrix is likely to be extremely sparse, i.e., many ratings could be missing since most customers typically rate only a few products. Thus, the task here is matrix completion – we need to predict the missing ratings so that it can be used for downstream processing such as displaying the top recommendations for each customer.
The LMF model assumes that the ratings matrix can be approximately generated as a product of two factor matrices, L and R, which are much smaller than D (lower rank). The idea is that the product L * R will approximately reconstruct the existing ratings and also automatically predict the missing ratings in D. More precisely, for each available rating (i,j,v) in D, we have (L x R) [i,j] ≈ v, while for each missing rating (i',j') in D, the predicted rating is (L x R) [i',j']. The model has a parameter r, which dictates the rank of the factor matrices, i.e., L is m x r, while R is r x n.
Matrix Completion in ORAAH
LMF can be invoked out-of-the-box using the routine orch.lmf. An execution based on the above example is shown below. The dataset of ratings is in a CSV file on HDFS with the schema above (named “retail_ratings” here), while the output (the factor matrices and metadata) are written to an HDFS folder (named “retail_model” here).
input <- hdfs.attach("retail_ratings")
fit <- orch.lmf(input)
# Export the model into R memory
lr <- orch.export.fit(fit)
# Compute the prediction for the point (100, 50)
# First column of lr$L contains the userid
userid <- lr$L[,1] == 100 # find row corresponding to user id 100
L <- lr$L[, 2:(rank+1)]
#First column contains the itemid
itemid <- lr$R[,1] == 50 # find row corresponding to item id 50
R <- lr$R[, 2:(rank+1)]
# dot product as sum of terms obtained through component wise multiplication
pred <- sum(L[userid,] * R[itemid,])
The factor matrices can be transparently loaded into R for further inspection and for ad-hoc predictions of specific customer ratings using R. The algorithm we use for training the LMF model is called Incremental Gradient Descent (IGD), which has been shown to be one of the fastest algorithms for this task [1, 2].
The entire set of arguments for the function orch.lmf along with a brief description of each and their default values is given in the table below. The latin parameter configures the degree of parallelism for executing IGD for LMF on Hadoop [2]. ORAAH sets this automatically based on the dimensions of the problem and the memory available to each Mapper. Each Mapper fits its partition of the model in memory, and the multiple partitions run in parallel to learn different parts of the model. The last five parameters configure IGD and need to be tuned by the user to a given dataset since they can impact the quality of the model obtained.
![]()
ORAAH also provides routines for predicting ratings as well as for evaluating the model (computing the error of the model on a given labeled dataset) on a large scale over HDFS-resident datasets. The routine for prediction of ratings is predict and for evaluating is orch.evaluate.
Other Matrix Factorization Tasks
While LMF is primarily used for matrix completion tasks, it can also be used for other matrix factorization tasks that arise in text mining, computer vision, and bio-informatics, e.g., dimension reduction and feature extraction. In these applications, the input data matrix need not necessarily be sparse. Although many zeros might be present, they are not treated as missing values. The goal here is simply to obtain a low-rank factorization D ≈ L x R as accurately as possible, i.e., the product L x R should recover all entries in D, including the zeros. Typically, such applications use a Non-Negative Matrix Factorization (NMF) approach due to non-negativity constraints on the factor matrix entries. However, many of these applications often do not need non-negativity in the factor matrices. Using NMF algorithms for such applications leads to poorer-quality solutions. Our implementation of matrix factorization for such NMF-style tasks can be invoked out-of-the-box in ORAAH using the routine orch.nmf, which has the same set of arguments as LMF.
Experimental Results & Comparison with Apache Mahout
We now present an empirical evaluation of the performance, quality, and scalability of the ORAAH LMF tool based on IGD and compare it to the most widely used off-the-shelf tool for LMF on Hadoop – an implementation of the ALS algorithm from Apache Mahout [3].
All our experiments are run on an Oracle Big Data Appliance Hadoop cluster with nine nodes, each with Intel Xeon X5675 12-core 3.07GHz processors, 48 GB RAM, and 20 TB disk. We use 256MB HDFS blocks and 10 reducers for MapReduce jobs.
We use two standard public datasets for recommendation tasks – MovieLens10M (referred to as MLens) and Netflix – for the performance and quality comparisons (insert URL). To study scalability aspects, we use several synthetic datasets of different sizes by changing the number of rows, number of columns, and/or number of ratings. The table below presents the data set statistics.
![]()
Results: Performance and Quality
We first present end-to-end overview of the performance and quality achieved by our implementation and Mahout on MLens and Netflix. The rank parameter was set at 50 (a typical choice for such tasks) and the other parameters for both tools were chosen using a grid search. The quality of the factor matrices was determined using the standard measure of root mean square error (RMSE) [2]. We use a 70%-15%-15% Wold holdout of the datasets, i.e., 70% for training, 15% for testing, and 15% for validation of generalization error. The training was performed until 0.1% convergence, i.e., until the fractional decrease in the training RMSE after every iteration reached 0.1%. The table below presents the results.
![]()
1. ORAAH LMF has a faster performance than Mahout LMF on the overall training runtime on both datasets – 1.8x faster on MLens and 2.3x faster on Netflix.
2. The per-iteration runtime of ORAAH LMF is much lower than that of Mahout LMF – between 4.4x and 5.4x.
3. Although ORAAH LMF runs more iterations than Mahout LMF, the huge difference in the per-iteration runtimes make the overall runtime smaller for ORAAH LMF.
4. The training quality (training RMSE) achieved is comparable across both tools on both datasets. Similarly, the generalization quality is also comparable. Thus, ORAAH LMF can offer state-of-the-art quality along with faster performance.
Results: Scalability
The ability to scale along all possible dimensions of the data is key to big data analytics. Both ORAAH LMF and Mahout LMF are able to scale to billions of ratings by parallelizing and distributing computations on Hadoop. But we now show that unlike Mahout LMF, ORAAH LMF is also able to scale to hundreds of millions of customers (m) and products (n), and also scales well with the rank results along these three dimensions – m, n, and r. parameter (r, which affects the size of the factor matrices). The figure below presents the scalability.
![]()
1. Figures (A) and (B) plot the results for the Syn-row and Syn-col datasets, respectively (r = 2). ORAAH LMF scales linearly with both number of rows (m) and number of columns (n), while Mahout LMF does not show up on either plot because it crashes at all these values of m. In fact, we verified that Mahout LMF does not scale beyond even m = 20 M! The situation is similar with n. This is because Mahout LMF assumes that the factor matrices L and R fit entirely in the memory of each Mapper. In contrast, ORAAH LMF uses a clever partitioning scheme on all matrices ([2]) and can thus scale seamlessly on all dataset dimensions.
2. Figure (C) shows the impact of the rank parameter r. ORAAH LMF scales linearly with r and the per-iteration runtime roughly doubles between r = 20 and r = 100. However, the per-iteration runtime of Mahout LMF varies quadratically with r, and in fact, increases by a factor of 40x between r = 20 and r = 100! Thus, ORAAH LMF is also able to scale better with r.
3. Finally, on the tera-scale dataset Syn-tera with 1 billion rows, 10 million columns, and 20 billion ratings, ORAAH LMF (for r = 2) finishes an iteration in just under 2 hours!
Acknowledgements
The matrix factorization features in ORAAH were implemented and benchmarked by Arun Kumar during his summer internship at Oracle under the guidance of Vaishnavi Sashikanth. He is pursuing his PhD in computer science from the University of Wisconsin-Madison. This work is the result of a collaboration between Oracle and the research group of Dr. Christopher Ré, who is now at Stanford University. Anand Srinivasan helped integrate these features into ORAAH.
References
[1] Towards a Unified Architecture for in-RDBMS Analytics. Xixuan Feng, Arun Kumar, Benjamin Recht, and Christopher Ré. ACM SIGMOD 2012.
[2] Parallel Stochastic Gradient Algorithms for Large-Scale Matrix Completion. Benjamin Recht and Christopher Ré. Mathematical Programming Computation 2013.
[3] Apache Mahout. http://mahout.apache.org/.










 Ready to dive into the Internet of Things? Take the new, free, online course "
Ready to dive into the Internet of Things? Take the new, free, online course "





") I didn't took a picture in the bathroom ...
I didn't took a picture in the bathroom ... 











![image[7][2][2][2]](http://soacommunity.files.wordpress.com/2013/04/image7222.png?w=20&h=20&h=20 "image[7][2][2][2]")
![clip_image002[8][4][2][2][2]](http://soacommunity.files.wordpress.com/2013/04/clip_image00284222.jpg?w=26&h=23&h=23 "clip_image002[8][4][2][2][2]")

